Logistic Regression in ML
Table of Contents:
- What is Logistic Regression?
- Characteristics of Logistic Regression
- How Logistic Regression Works
- Types of Logistic Regression
- Binomial Logistic Regression
- Multinomial Logistic Regression
- Ordinal Logistic Regression
- Comparison of Logistic Regression Types
- Real-World Applications
Content Highlight:
Logistic regression is a classification algorithm used to predict categorical outcomes. It is categorized into three types: Binomial Logistic Regression, which deals with two possible outcomes (e.g., Yes/No, Pass/Fail); Multinomial Logistic Regression, which handles three or more unordered categories (e.g., Dog, Cat, Rabbit); and Ordinal Logistic Regression, which classifies ordered categories (e.g., Low, Medium, High). Each type is suited for different classification problems, helping in medical diagnosis, spam detection, risk assessment, and customer segmentation.
What is support vector machine (SVM)?
Support Vector Machine (SVM) is one of the most powerful and widely used algorithms in supervised learning. It is effective for both classification and regression tasks, although it is most often applied to classification problems in machine learning.
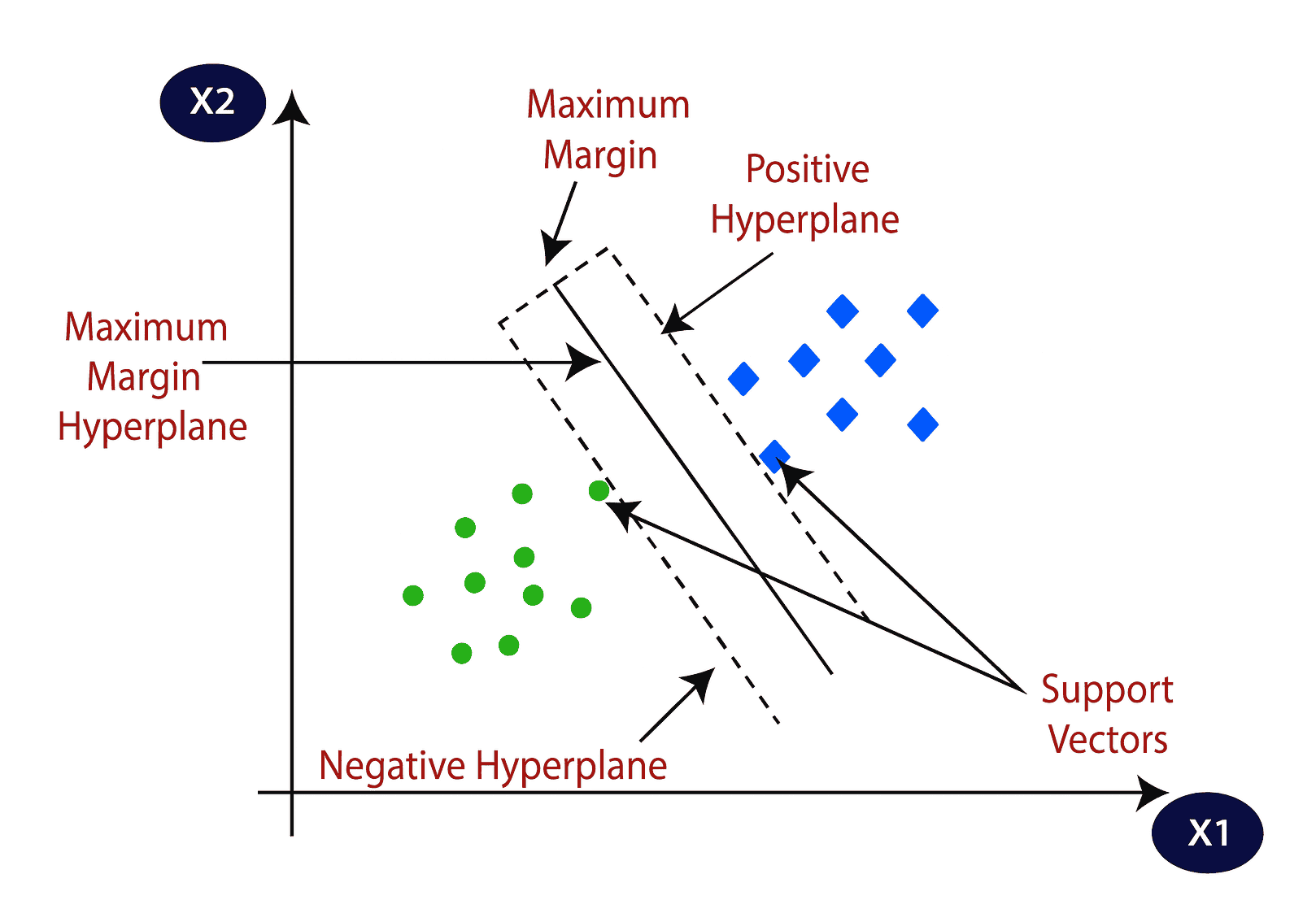
The core idea behind the SVM algorithm is to find the most optimal decision boundary that can separate data points belonging to different classes. This boundary, known as a hyperplane, helps divide an n-dimensional feature space in such a way that new, unseen data points can be classified accurately.
What makes SVM unique is the way it constructs this hyperplane. Rather than relying on all the data points, it focuses only on the most critical ones—the points that lie closest to the decision boundary. These are known as support vectors, and they play a pivotal role in shaping the hyperplane. The presence of these support vectors is what gives the algorithm its name: Support Vector Machine.
Imagine a visual representation where two categories of data points are clearly separated by a straight line or curve. The SVM model identifies the boundary that not only separates the classes but also maintains the maximum possible margin between them. This margin ensures that the model is robust and generalizes well to new data.
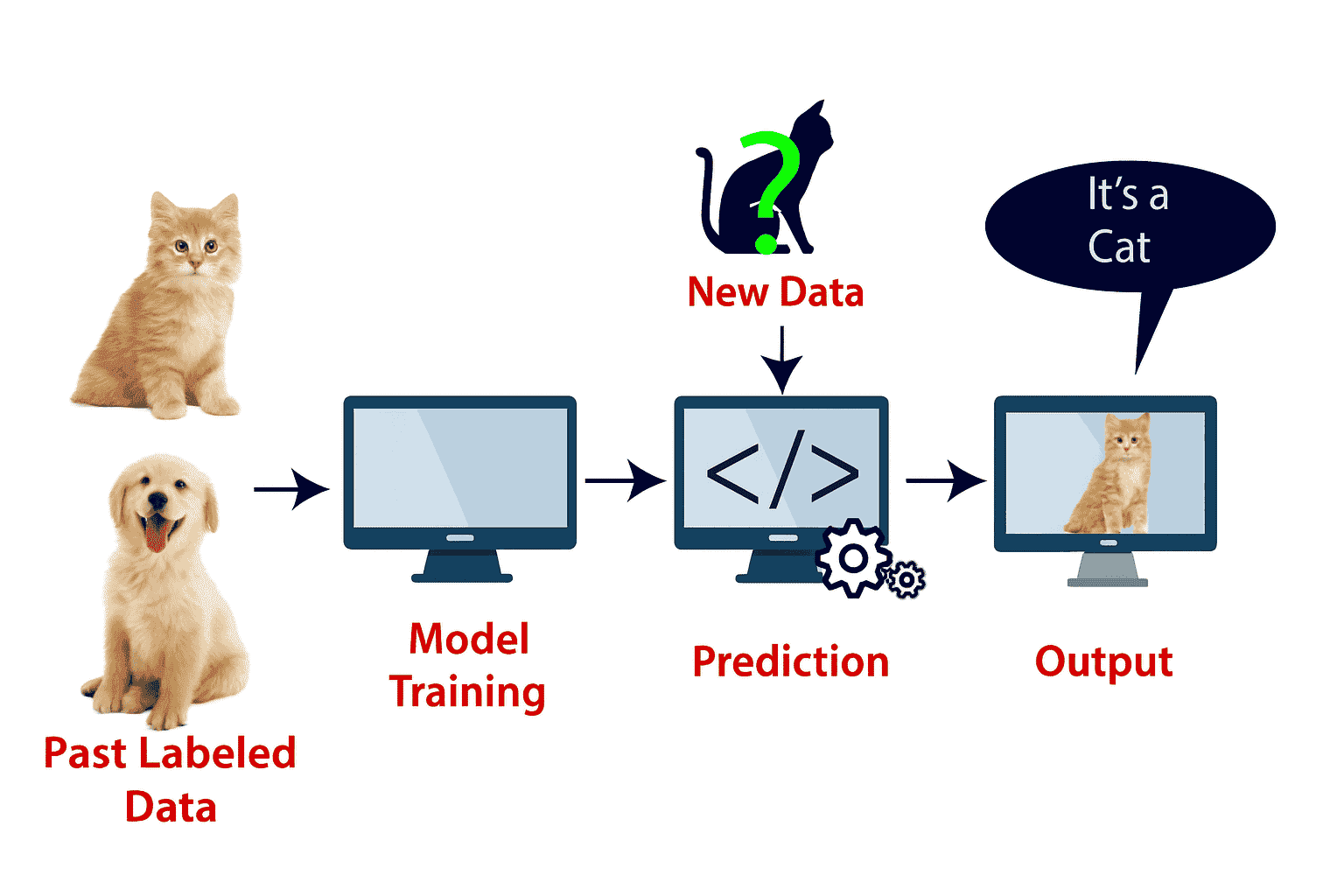
Example: Let's understand how Support Vector Machine (SVM) works with a real-world analogy. Imagine you encounter an unusual animal—it looks like a cat, but it also shares some features commonly found in dogs. You're unsure whether it's a cat or a dog.
To build a model that can accurately identify such ambiguous cases, you can use the SVM algorithm. First, you train your SVM model using a large dataset of images containing labeled examples of both cats and dogs. During training, the model learns to recognize the unique features that distinguish one class from the other.
Now, when you present this strange animal to the trained model, the SVM classifier analyzes it by referencing the support vectors—the most critical examples from each class that lie closest to the decision boundary. These support vectors help define the optimal hyperplane that separates the two categories.
Based on the position of this new input in the feature space, and its proximity to the support vectors, the SVM model classifies the animal. If it shares more similarities with the extreme features of cats, the model confidently labels it as a cat.
Below is a visual representation illustrating how SVM draws a decision boundary between two classes (cats and dogs) using support vectors: