Informed search in AI
Table of Content:
- What is informed search in artificial intelligence (AI)?
- What is pure heuristic search in AI?
- Best-first Search Algorith
- Example of Best-first Search Algorithm
- Advantages of Best-first Search Algorithm
- Disadvantages of Best-first Search Algorithm
- A* Search Algorithm
- Example of A* Search Algorithm
- Advantages of A* Search Algorithm
- Disadvantages of A* Search Algorithm
Content Highlight:
Informed search algorithms like A* and greedy best-first search, integral to AI, leverage heuristic information for efficient problem-solving. These algorithms, exemplified by their prioritization of promising paths, significantly enhance search efficiency in large spaces.
Despite their advantages, challenges exist, such as A*'s potential memory consumption and the need for well-designed heuristics. Greedy best-first search, while efficient, may face issues like getting stuck in local optima. Understanding the strengths and limitations of these algorithms is crucial for effective problem-solving in diverse scenarios.
What is informed search in artificial intelligence (AI)?
An informed search algorithm is a type of search algorithm used in artificial intelligence and computer science to find a solution to a problem more efficiently by utilizing heuristic information or domain-specific knowledge. Unlike uninformed search algorithms, which explore the search space without considering the characteristics of the problem, informed search algorithms make use of additional information to guide the search towards more promising paths. The goal is to improve the efficiency of the search process by making informed decisions about which nodes to explore next.
Common examples of informed search algorithms include A* (A-star) and greedy best-first search, where a heuristic function is employed to estimate the cost or distance to the goal from a given state. Informed search algorithms are particularly useful in situations where the search space is large, and a systematic exploration would be computationally expensive. By incorporating domain-specific knowledge, these algorithms can significantly reduce the time and resources required to find a solution to complex problems.
The informed search algorithm is especially advantageous when dealing with a large search space. Leveraging the concept of heuristic, it is often referred to as Heuristic search. Unlike uninformed search algorithms that explore the search space blindly, informed search algorithms employ heuristic information or domain-specific knowledge to make more informed decisions about which nodes to explore. This approach enhances the efficiency of the search process, guiding it towards more promising paths and reducing the computational burden associated with exhaustive exploration.
Heuristic function: In the context of Informed Search, a heuristic function plays a crucial role in identifying the most promising path towards a goal. This function takes the current state of the agent as its input and provides an estimation of the proximity of the agent to the goal. While the heuristic method may not always yield the optimal solution, it is designed to guarantee finding a good solution within a reasonable time frame. Represented by h(n), the heuristic function calculates the cost of an optimal path between a pair of states, offering a valuable metric for guiding the search algorithm. Importantly, the value of the heuristic function is always positive, reflecting its role in estimating how close a given state is to reaching the ultimate goal.
Admissibility of the heuristic function is given as below:
h(n) <= h*(n)
In the context of Informed Search, where h(n) represents the heuristic cost and h*(n) denotes the estimated cost, it is a requirement that the heuristic cost (h(n)) must be less than or equal to the estimated cost (h*(n)). This condition ensures that the heuristic function provides a valid and reliable estimation for guiding the search algorithm effectively.
What is pure heuristic search in AI?
Pure heuristic search represents the simplest form of heuristic search algorithms. It expands nodes based on their heuristic value h(n), utilizing two lists: OPEN and CLOSED. Nodes that have already been expanded are placed in the CLOSED list, while nodes yet to be expanded are stored in the OPEN list.
During each iteration, the algorithm expands the node n with the lowest heuristic value, generating all its successors. Subsequently, n is placed in the CLOSED list. This process continues until a goal state is found.
In the realm of informed search, two primary algorithms are noteworthy:
- Best First Search Algorithm (Greedy search)
- A* Search Algorithm
1. Best-first Search Algorithm (Greedy Search):
The greedy best-first search algorithm always prioritizes the path that seems most promising at the current moment. Combining elements of both depth-first and breadth-first search algorithms, it relies on the heuristic function to guide its exploration. This algorithm enables the advantages of both strategies, allowing for the selection of the most promising node at each step. In best-first search, node expansion is based on proximity to the goal, with the closest cost estimated by the heuristic function, i.e., (f(n) = g(n)), where (h(n)) represents the estimated cost from node (n) to the goal.
The greedy best-first algorithm is implemented using a priority queue. The steps for this algorithm are as follows:
- Step 1: Place the starting node into the OPEN list.
- Step 2: If the OPEN list is empty, stop and return failure.
- Step 3: Remove the node (n) from the OPEN list with the lowest value of (h(n)) and place it in the CLOSED list.
- Step 4: Expand node (n) and generate its successors.
- Step 5: Check each successor to determine if any node is a goal node. If found, return success and terminate the search; otherwise, proceed to Step 6.
- Step 6: For each successor node, the algorithm checks the evaluation function (f(n)) and verifies whether the node is in either the OPEN or CLOSED list. If not in either list, add it to the OPEN list.
- Step 7: Return to Step 2.
Example of Best-first Search Algorithm (Greedy Search):
Consider the following search problem, and let's traverse it using the Greedy Best-First Search algorithm. At each iteration, nodes are expanded using the evaluation function (f(n) = h(n)).
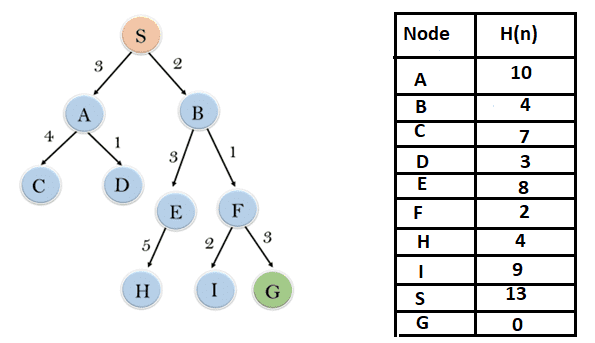
In this search example, we are using two lists which are OPEN and CLOSED Lists. Following are the iterations for traversing the above example.
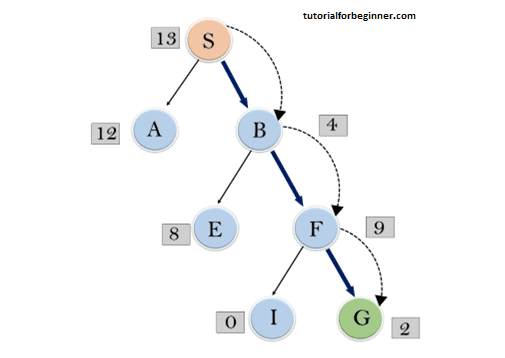
Expand the nodes of S and put in the CLOSED list:
- Initialization: Open [A, B], Closed [S]
- Iteration 1: Open [A], Closed [S, B]
-
Iteration 2:
- Open [E, F, A], Closed [S, B]
- Open [E, A], Closed [S, B, F]
-
Iteration 3:
- Open [I, G, E, A], Closed [S, B, F]
- Open [I, E, A], Closed [S, B, F, G]
Hence the final solution path will be: S ----> B -----> F ----> G
Time Complexity: The worst-case time complexity of Greedy Best-First Search is (O(bm)).
Space Complexity: The worst-case space complexity of Greedy Best-First Search is (O(bm)), where m is the maximum depth of the search space.
Completeness: Greedy Best-First Search is also incomplete, even if the given state space is finite.
Optimal: Greedy Best-First Search algorithm is not optimal.
Advantages of Best-first Search Algorithm:
- Efficiency: Greedy best-first search excels in efficiently selecting paths based on the heuristic function, prioritizing nodes that appear most promising.
- Adaptability: Combining aspects of depth-first and breadth-first search, the algorithm adapts to different scenarios, leveraging the advantages of both strategies.
- Heuristic Guidance: The algorithm utilizes the heuristic function to estimate the closest cost to the goal, guiding the search towards more relevant nodes.
- Priority Queue Implementation: The use of a priority queue enhances the algorithm's efficiency by facilitating the retrieval of nodes with the lowest heuristic values.
- Promising Node Selection: At each step, the algorithm selects the most promising node for expansion, contributing to a more focused and goal-oriented search.
Disadvantages of Best-first Search Algorithm:
- Local Optima: Greedy best-first search may get stuck in local optima by favoring paths that seem locally optimal but may not lead to the overall best solution.
- Shortsighted Decisions: The algorithm's focus on immediate gains based on the heuristic value can result in shortsighted decisions, neglecting the broader search space.
- Uninformed Exploration: While using heuristics, the algorithm lacks a global perspective, potentially missing more promising paths that may be discovered through a more informed exploration.
- Goal Dependency: The efficiency of the algorithm heavily relies on the accuracy of the heuristic function, and suboptimal heuristics can lead to less effective searches.
- Incomplete Solutions: Greedy best-first search might provide incomplete solutions, as its focus on local optimization may lead to overlooking essential elements of the search space.
2. A* Search Algorithm:
A* search is a widely recognized form of best-first search that incorporates the use of a heuristic function h(n) and the cost to reach the node n from the start state g(n). Combining features of both Uniform Cost Search (UCS) and greedy best-first search, A* efficiently addresses problems by finding the shortest path through the search space. This algorithm, characterized by the sum g(n) + h(n), provides an optimal solution faster by expanding a reduced search tree.
The A* search algorithm utilizes both the heuristic function and the cost to reach a node, allowing the combination of these costs into a fitness number. This fitness number serves as a key factor in guiding the algorithm towards the most promising paths. Similar to UCS, A* uses \(g(n) + h(n)\) as its evaluation function, emphasizing a balanced consideration of both the actual cost and the heuristic estimate.
This approach results in the A* algorithm efficiently exploring the search space, expanding fewer nodes in the process, and ultimately providing an optimal result in a shorter timeframe. The use of heuristic information ensures a more informed search, making A* a powerful and widely applied algorithm in various problem-solving scenarios.
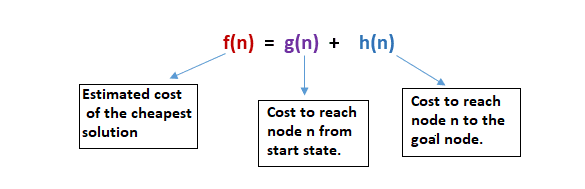
Note: At each point in the search space, only nodes with the lowest value of f(n) are expanded in the A* search algorithm. This strategy ensures that the algorithm consistently prioritizes the most promising paths, facilitating an efficient exploration of the search space. The termination condition for the algorithm is met when the goal node is found.
Algorithms of A* search:
- Step 1: Place the starting node in the OPEN list.
- Step 2: Check if the OPEN list is empty. If empty, return failure and stop.
- Step 3: Select the node from the OPEN list with the smallest value of the evaluation function (g+h). If node n is the goal node, return success and stop; otherwise,
-
Step 4:
- Expand node n and generate all of its successors. Put n into the closed list.
- For each successor n', check whether n' is already in the OPEN or CLOSED list. If not, compute the evaluation function for n' and place it in the OPEN list.
- Step 5: If node n' is already in OPEN and CLOSED, attach it to the back pointer reflecting the lowest g(n') value.
- Step 6: Return to Step 2.
Example of A* Search:
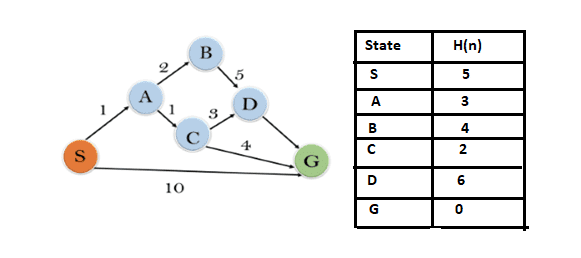
In this illustrative example, we embark on traversing a given graph employing the A* algorithm. The heuristic values for all states are presented in the table below. To determine the suitability of each state, we calculate the f(n) using the formula f(n) = g(n) + h(n), where g(n) represents the cost to reach any node from the start state.
Throughout this traversal, we make use of OPEN and CLOSEDlists:
We'll use the OPEN and CLOSED lists here.
Solution:
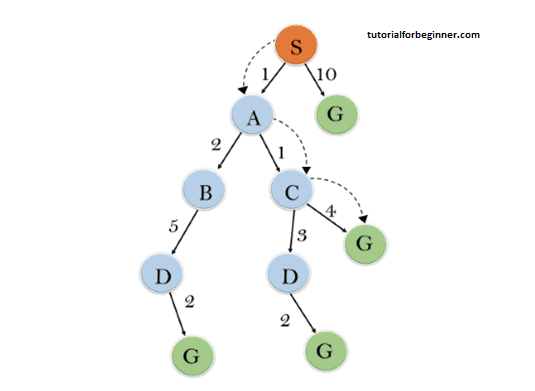
- Initialization: {(S, 5)}
- Iteration 1: {(S → A, 4), (S → G, 10)}
- Iteration 2: {(S → A → C, 4), (S → A → B, 7), (S → G, 10)}
- Iteration 3: {(S → A → C → G, 6), (S → A → C → D, 11), (S → A → B, 7), (S → G, 10)}
- Iteration 4: The final result is S → A → C → G, providing the optimal path with a cost of 6.
- A* Algorithm Behavior: A* algorithm returns the first occurrence of a path and does not explore all remaining paths.
- Heuristic Quality: The efficiency of the A* algorithm relies on the quality of the heuristic employed.
- Node Expansion: A* algorithm expands all nodes that satisfy the condition \(f(n)\).
- Completeness: A* algorithm is complete under the following conditions:
- Branching factor is finite.
- Cost at every action is fixed.
- Optimality: A* search algorithm is optimal if it satisfies the following two conditions:
- Admissible: The heuristic function h(n) should be an admissible heuristic for A* tree search, meaning it is optimistic in nature.
- Consistency: Consistency is required for A* graph-search.
- Time Complexity: The time complexity of A* search algorithm depends on the heuristic function, and the number of nodes expanded is exponential to the depth of the solution (\(d\)). Thus, the time complexity is \(O(b^d)\), where \(b\) is the branching factor.
- Space Complexity: The space complexity of A* search algorithm is O(b d).
Advantages of A* Search:
- Optimality:A* search guarantees optimality in finding the shortest path from the start node to the goal node, provided certain conditions are met.
- Completeness:The algorithm is complete, ensuring that it will find a solution if one exists in the search space.
- Efficiency: A* is highly efficient due to its intelligent node expansion strategy, which focuses on the most promising paths.
- Informed Search:The algorithm utilizes heuristic information effectively, guiding the search towards more relevant areas of the search space.
- Admissibility:When the heuristic function is admissible, meaning it never overestimates the true cost to reach the goal, A* ensures an accurate and reliable search.
Disadvantages of A* Search:
- Memory Usage: A* search can consume a significant amount of memory, especially in scenarios with large search spaces or when the optimal path is extensive.
- Time Complexity: In certain cases, the time complexity of A* can be high, particularly when the heuristic function is not well-designed or when the search space is vast.
- Admissibility Requirement: The admissibility requirement for the heuristic function might be challenging to satisfy in some problem domains, limiting the algorithm's effectiveness.
- Difficulty in Heuristic Design: Crafting an effective heuristic function that accurately estimates the true cost to reach the goal can be challenging and may require domain-specific knowledge.
- Not Suitable for All Domains: A* may not be the best choice for certain types of problems, particularly those where the path cost is not well-defined or the search space is dynamic.